
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- codejam
- 파버스
- 데이트
- 스파게티
- 스코티쉬 스트레이트
- 발산맛집
- CDJ
- 치명적 귀여움
- 냥스토리
- 고양이
- 고양이는 언제나 귀엽다
- 발산역 근처 카페
- 발산
- 부모님과
- 먹기좋은곳
- 레스토랑
- 냥냥
- 스테이크
- 소호정본점
- 안동국시
- CodeJam 2017 Round 1B
- RED CAT COFFEE X LOUNGE
- 카페
- coffee
- 소호정
- 커플
- A. Steed 2: Cruise Control
- 냥이
- 양재맛집
- 파머스테이블
- Today
- Total
hubring
k-인접이웃 분류모형 본문
소개
k-인접이웃(K-nearest neighbor 이하 k-NN)분류모형은 새로운 데이터(설명변수값)에 대해 이와 가장 유사한(거리가 가까운) k-개의 과거 자료(설명변수값)의 결과(반응변수, 집단)를 이용 다수결(magority vote)로 분류한다.
-> 분류나 회귀에 사용되는 비모수 방식.
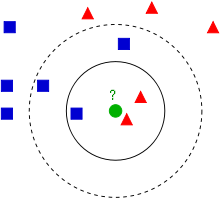
과거자료를 이용하여 미리 분류모형을 수립하는 것이 아니라, 과거 데이터를 저장만 해두고 필요시 비교를 수행하는 방식이다. k 값의 선택에 따라 새로운 데이터에 대한 분류의 결과가 달라짐에 유의하여야 한다.
k-NN은 반응변수가 범주형인 경우에는 분류(classification)의 목적으로, 반응변수가 연속형인 경우에는 회귀(regression)의 목적으로 사용될 수 있다.
- k-NN 분류에서 출력은 소속된 항목이다. 객체는 k개의 최근접 이웃 사이에서 가장 공통적인 항목에 할당되는 객체로 과반수 의결에 의해 분류된다(k는 양의 정수이며 통상적으로 작은 수). 만약 k = 1 이라면 객체는 단순히 하나의 최근접 이웃의 항목에 할당된다.
- k-NN 회귀에서 출력은 객체의 특성 값이다. 이 값은 k개의 최근접 이웃이 가진 값의 평균이다.
k-NN은 기계학습분야에서 가장 단순한 알고리즘이다. 이 알고리즘은 지역 정보만으로 근사되며, 모든 계산이 이루어진 후에 분류가 이루어지는 특징으로 인해 사례기반학습(instance-based learning) 또는 게으른 학습(lazy learning)의 한 유형으로 볼 수 있다.
사례기반학습은 메모리에 저장되어 있는 과거 훈련자료로부터 직접 결과가 도출되므로 메모리기반학습(memory-based learning)이라고 불리기도 한다.
k-NN은 분류와 회귀 모두 더 가까운 이웃일수록 더 먼 이웃보다 평균에 더 많이 기여하도록 이웃의 기여에 가중치를 주는 것이 유용할 수 있다. 예를 들어, 가장 흔한 가중치 스키마는 d가 이웃까지의 거리일 때 각각의 이웃에게 1/d의 가중치를 주는 것이다.
k-NN 알고리즘의 단점은 데이터의 지역 구조(local structure)에 민감하다는 것이다. 이 알고리즘은 유명한 기계 학습 기법, k-평균과 아무 관련이 없으므로 혼동하지 않아야 한다.
tensorflow 예제
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# import MNIST data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("./data/", one_hot = True)
print("훈련 이미지:", mnist.train.images.shape)
print("훈련 라벨:", mnist.train.labels.shape)
print("테스트 이미지:", mnist.test.images.shape)
print("테스트 라벨:", mnist.test.labels.shape)
print("검증 이미지:", mnist.validation.images.shape)
print("검증 라벨:", mnist.validation.labels.shape)
mnist_idx = 1
print('[label]')
print('one-hot vector label = ', mnist.train.labels[mnist_idx])
print('number label = ', np.argmax(mnist.train.labels[mnist_idx]))
print('\n')
# region k-NN algorithm
# x_data_train : training data 전부의 784개의 픽셀
# y_data_train : training data 전부의 숫자 라벨
# x_data_test : test data 한개 784개의 픽셀
x_data_train = tf.placeholder(tf.float32, [None, 784])
y_data_train = tf.placeholder(tf.float32,[None, 10])
x_data_test = tf.placeholder(tf.float32, [784])
paramK = tf.placeholder(tf.int32)
# distance : K-Nearest Neighbor - 오차 거리를 구한다(유클리드 거리)
distance = tf.reduce_sum(tf.abs(tf.add(x_data_train, tf.negative(x_data_test))), reduction_indices=1)
# nearest k points
_, top_k_indices = tf.nn.top_k(tf.negative(distance), k=paramK) #가장 가까운 이미지 K개의 인덱스를 가져온다.
top_k_label = tf.gather(y_data_train, top_k_indices) #Index에 해당하는 숫자 라벨를 가져온다.
sum_up_predictions = tf.reduce_sum(top_k_label, axis=0) #공통되는 숫자 라벨의 개수를 더한다.
prediction = tf.argmax(sum_up_predictions) #가장 가까운 숫자값을 구한다.
# endregion
print("--------- TEST -----------")
# 학습을 위해서 기준 데이터들의 개수를 Batch size로 잡음
# 1000개에 대해 테스트 해본다
train_images, train_labels = mnist.train.next_batch(3000)
test_images, test_labels = mnist.test.next_batch(1000)
# Tensorflow 세션 실행
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
# 정확도를 초기화
accuracy = 0
confusion_matrix = [[0 for i in range(10)] for j in range(10)]
for i in range(len(test_images)):
# k-NN 알고리즘 수행 예측된 숫자를 구한다.
pre_label = sess.run(prediction, feed_dict={x_data_train: train_images, y_data_train: train_labels, x_data_test: test_images[i, :], paramK : 4})
real_label = np.argmax(test_labels[i])
#nn_index의 라벨값과 실제 라벨값을 비교한다.
print("테스트 횟수 : ", i)
print("실제값 : ", real_label)
print("예측값 : ", pre_label)
confusion_matrix[real_label][pre_label] +=1
# 예측도 파악
# KNN은 비교 데이터에서 가장 가까운 것을 찾는 것이므로 매번 확률을 갱신해야한다(가중치를 찾는게 아니다)
# 가장 가까운 것이 무엇이 될지 모름
if pre_label == real_label :
accuracy += 1./len(test_images)
#else :
# 잘못 예측한 이미지 보기
# plt.figure(figsize = (5, 5))
# image = np.reshape(test_images[i], [28, 28])
# plt.imshow(image, cmap = 'Greys')
# plt.show()
print("--------- RESULT -----------")
print("예측 정확도 : ", round(accuracy*100, 2)," %")
print("The resulting confusion matrix")
# confusion matrix 생성
for i in range(10):
print(confusion_matrix[i])
참고 코드자료
http://marubon-ds.blogspot.com/2017/09/knn-k-nearest-neighbors-by-tensorflow.html
How to write kNN by TensorFlow
Deep learning and Machine learning methods blog
marubon-ds.blogspot.com
Mathpresso 머신 러닝 스터디 — 6. 분류(Classification)
.
medium.com
추가 참고자료
k-NN 성능 확인
https://benlevinson.com/projects/comparing-knn-svm-mnist
Comparing classifiers on the MNIST Data Set
Comparing classifiers on the MNIST Data Set 20 December, 2017 | This is a adaptation of a report written in collaboration with Louisa Lee (with some modfications) from my Machine Learning class in Fall 2017. Introduction The MNIST data set is a widely popu
benlevinson.com
k-NN 상세 및 라이브러리 활용
https://scikit-learn.org/stable/modules/neighbors.html
1.6. Nearest Neighbors — scikit-learn 0.21.3 documentation
1.6. Nearest Neighbors sklearn.neighbors provides functionality for unsupervised and supervised neighbors-based learning methods. Unsupervised nearest neighbors is the foundation of many other learning methods, notably manifold learning and spectral cluste
scikit-learn.org
'AI > Tensorflow' 카테고리의 다른 글
| TensorFlow로 파일에서 데이터 읽어오기 (0) | 2021.03.05 |
|---|---|
| Multi-variable linear regression (0) | 2021.02.24 |
| Linear Regression의 cost 최소화 원리 (0) | 2021.02.23 |
| Linear Regression (0) | 2021.02.23 |
| 머신 러닝 기본 (0) | 2021.02.23 |


