
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 발산역 근처 카페
- 파버스
- 카페
- A. Steed 2: Cruise Control
- CDJ
- CodeJam 2017 Round 1B
- 스테이크
- 양재맛집
- RED CAT COFFEE X LOUNGE
- 소호정
- 데이트
- 치명적 귀여움
- 냥스토리
- codejam
- 먹기좋은곳
- 소호정본점
- 안동국시
- 발산맛집
- 발산
- 스코티쉬 스트레이트
- 스파게티
- 냥냥
- 고양이
- coffee
- 냥이
- 파머스테이블
- 커플
- 고양이는 언제나 귀엽다
- 부모님과
- 레스토랑
- Today
- Total
hubring
[DB] 다양한 Database 사용 이유와 종류 본문
얼마 전 AWS 2019 Summit에 참관하여 들었던 강연에서 Amazon CTO Werner Vogels의 블로그의
A one size fit all database doesn't fit anyone 글을 참고한 내용이 있었는데
관계형 데이터베이스뿐만 아니라 비관계형 데이터베이스의 종류에 대해 알고 나갈 수 있어 좋은 자료라 생각돼 해당 강연 내용과 함께 정리하여 공유합니다.
왜 다양한 데이터베이스가 필요한가?
A one size fits all database dosen't fit anyone - Werner Vogels

블로그의 제목에서 "A one size fit all Database"는 프리사이즈 옷과 같은 단일체 데이터베이스를 뜻하며
오늘날 이 단일체의 데이터베이스가 어디서나 맞다고 볼 수 없다는 의미로 해석된다.
시대가 변화함에 따라 다양한 UseCase들이 생겨났고 하나의 데이터베이스론 요구에 맞게 만들 수 없는 경우가 발생하였다. 이에 개발자들은 여러 가지 특수 데이터베이스를 사용하여 고도로 분산된 응용 프로그램을 개발하기 시작하였다.
최근 개발자들은 복잡한 응용 프로그램(모놀리식)을 작은 조각(마이크로서비스)으로 분해한 다음 각 문제를 해결하는 데 가장 적합한 도구(데이터베이스)를 선택하여 각 요구 사례에 맞는 작업을 수행할 수 있도록 하고 있다.

우리는 수십 년 동안 응용 프로그램의 데이터나 형태 기능과 관계없이 데이터는 관계형으로 모델링 되어 사용해왔다. 이로
인하여 데이터베이스가 애플리케이션 요구사항의 데이터 모델을 주도하고 있었다.(요구사항에 맞는 데이터베이스를 사용할 수 없었으므로 관계형 데이터베이스에 맞게 요구사항의 데이터 모델을 변경하여 적용시킴)
하지만 오늘날의 모든 애플리케이션의 데이터 모델이나 요구사항이 관계형 모델과 일치하는 것이 아니라는 것이다.

Amazon DynamoDB(key-value DB)가 구축된 이유역시 위와 같은 데, Amazon이 당시 주요 상업용 데이터베이스의 한계를 뛰어넘었고 가용성, 확장성 및 성능 요구사항을 유지할 수 없었기 때문이다.
Amazon.com 비즈니스 요구에서 70%가 기본키를 사용하여 단일 행만 반환되는 Key-Value 참조 조회였고,
이는 참조 무결성 및 트랜잭션이 필요 없기 때문에 Key-Value 구조의 액세스 패턴이 관계형 데이터베이스와 같은 형태보다 잘 처리 될 수 있었다.
또한 Amazon의 성장과 규모로 인해 무한한 수평 스케일이 핵심 설계 포인트가 되었다.
이는 관계형 데이터베이스의 한계를 넘어 확장 가능한 비 관계형 데이터베이스 서비스 DynamoDB가 만들어지게 되었다.
이것은 관계형 데이터베이스가 현재의 개발 환경에서 유용하지 않거나 확장성, 고성능을 제공하지 않는다는 것을 의미하지는 않는다. 그 반대가 사실이다. AWS 역사상 가장 빠르게 성장하고 있는 서비스인 Amazon Aurora(관계형 데이터베이스)가 계속 남아있기 때문에 이 사실은 고객에 의해 입증되었다.
DynamoDB와 같이 목적에 따라 만들어진 데이터베이스를 요구사항에 맞게 선택함으로 고성능의 확장 가능한, 보다 기능적인 응용 프로그램을 작성할 수 있다.

다양한 데이터베이스 종류 소개
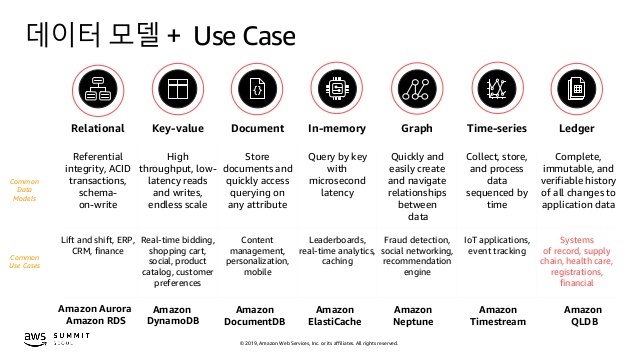
Relational 모델 (관계형 데이터베이스)

관계형 데이터베이스는 개발자가 데이터베이스의 행과 테이블 간의 관계 및 제약 조건뿐만 아니라
데이터베이스의 스키마도 정의 할 수 있다.
관계형 데이터베이스 내의 기능(응용 프로그램 코드 아님)을 사용하여 스키마를 적용하고 내부적으로 데이터의 참조 무결성을 보존한다.
관계형 데이터베이스의 일반적 사례로는 웹 응용 프로그램, 모바일 응용 프로그램, 엔터프라이즈 응용 프로그램 및 게임이 있다.
Key-Value 모델

Key-Value 데이터베이스는 파이션이 가능하여 다른 유형의 데이터베이스에서는 달성할 수 없는 수준에서 수평 확장이 가능하다.
액세스 패턴인 잘 알려진 키 값을 통해 데이터를 Get/Put을 하여 빠르게 접근하는 방식으로 게임이나 광고 기술 또는 IoT와 같은 사용 사례에 적합하다.
DynamoDB의 목적은 모든 규모의 작업 부하에 대해 일관된 한 자릿수 밀리초의 대기 시간을 제공하는 것이다.
이 일관된 기능은 Snapchat의 가장 큰 저장 쓰기 작업량을 포함하는 Snapchat Stories기능이 DynamoDB로 이동한 이유 중 큰 부분을 차지한다.
Document 모델

응용 프로그램 계층의 데이터가 일반적으로 JSON 문서로 표시되기 때문에 개발자는 문서 데이터베이스를 사용하기 쉽다.
개발자는 응용 프로그램 코드에서 사용하는 것과 동일한 문서 모델 형식을 이용하여 데이터를 유지할 수 있다.
Tinder는 DynamoDB의 유연한 스키마 모델을 사용하여 개발자의 효율성을 달성하는 고객의 한 예이다.
In-memory 모델
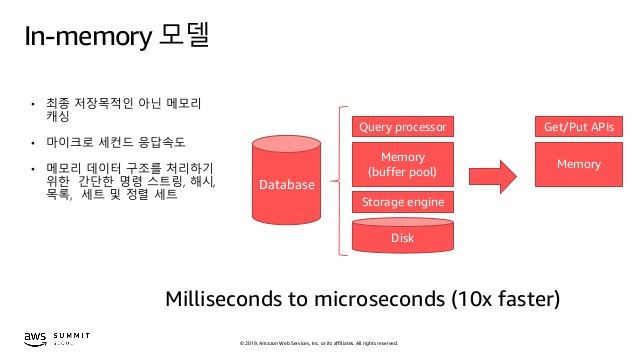
금융 서비스. 전자 상거래, 웹 및 모바일 애플리케이션에는 마이크로 초 응답 시간이 필요하고 언제든지 트래픽이 급증할 수 있는 리더 보드, 세션 저장소 및 실시간 분석과 같은 요구사항들이 있다.
Memcached 및 Redis와 같은 종류로 디스크 기반 데이터 저장소로는 처리 할 수 없는McDonald 's와 같이 대기 시간이 짧고 처리량이 많은 작업 부하를 처리한다.
Amazon DynamoDB Accelerator (DAX)는 In-Memory 모델의 또 다른 예로 DAX는 DynamoDB보다 더 빠르게 순서를 읽도록 만들어졌다.
Graph 모델
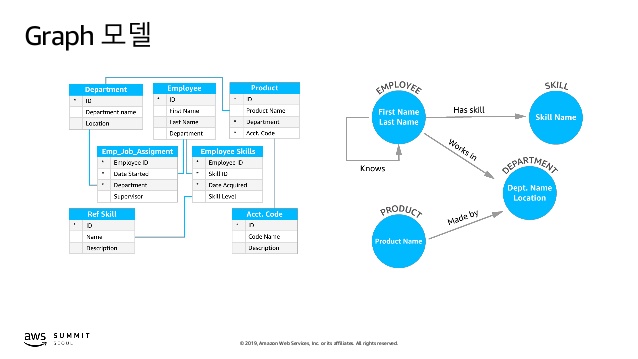
그래프 데이터베이스의 목적은 고도로 연결된 데이터 세트로 작업하는 애플리케이션을 쉽게 구축하고 실행할 수있게하는 것이다.
그래프 데이터베이스의 일반적인 사용 사례에는 소셜 네트워킹, 권장 사항 엔진, 사기 탐지 및 지식 그래프이다.
Amazon Neptune 은 완벽하게 관리되는 그래프 데이터베이스 서비스로 Property Graph 모델과 RDF (Resource Description Framework)를 모두 지원한다. TinkerPop과 RDF / SPARQL의 두 그래프 API를 선택할 수 있다.
Time series 모델

IoT 및 운영 애플리케이션용 서버 및 네트워크 로그, 센서 데이터 및 산업용 원격 측정 데이터와 같은 시계열 데이터를 수집, 저장 및 처리하기 위한 목적으로 구축된 시계열 데이터베이스 모델이다.
Amazon Timestream은 하루에 수조 건의 이벤트를 관계형 데이터베이스 비용의 1/10분로 처리하며 범용 데이터베이스보다 쿼리 성능이 최대 1,000배 빠릅니다.
Ledger 모델

완전관리형 원장 데이터베이스로, 중앙의 신뢰할 수 있는 기관이 소유하는 투명하고, 변경 불가능하며, 암호화 방식으로 검증 가능한 트랜잭션 로그를 제공한다.
Amazon QLDB는 모든 애플리케이션 데이터 변경 내용을 추적하며 완전하고 검증 가능한 시간대별 변경 기록을 유지한다.
정리
더 이상 모놀리식 응용 프로그램을 작성하지 않는 것처럼 개발자는 더 이상 응용 프로그램의 모든 사용 사례에 대해 단일 데이터베이스를 사용하지 않는다.
관계형 데이터베이스는 여전히 잘 사용되고 있으며 많은 UseCase에 여전히 적합하지만
Key-Value, Document, Graph, In-memory 및 검색을 위한 특수 데이터베이스는 기능, 성능 및 성능을 최적화하는 데 도움을 줄 수 있다.
참고 자료
지속적인 성능과 확장을 보장하는 마이크로 서비스 패턴 데이터베이스 구현하기 - 김용대 사업개발 담당, AWS / 주경호, 롯데정보통신 AWS Summit Seoul 2019 발표 자료
A one size fit all database doesn't fit anyone - Amazon CTO Werner Vogels 블로그